Introduction to GPT-3 and Open Source LLMs
Language models have revolutionized the field of natural language processing, enabling machines to understand and generate human-like text. Two significant players in this domain are GPT-3 (Generative Pre-trained Transformer 3) and open-source language models (LLMs). In this article, we will delve into the intricacies of these models and explore their similarities, differences, and respective advantages.
GPT-3, developed by OpenAI, is a behemoth of a language model. Boasting an astounding 175 billion parameters, it represents cutting-edge language processing capabilities. Trained on vast amounts of internet text data, GPT-3 demonstrates an exceptional understanding of language semantics and can generate coherent and contextually relevant text. Its versatility spans a wide range of applications, from content generation to translation and creative writing.
On the other hand, open-source LLMs provide an alternative approach to language modelling. These models, such as GPT-2, BERT, Transformer-XL, and XLNet, are freely available and come with accessible source code. Open-source LLMs offer flexibility and customization options, allowing developers to fine-tune the models for specific tasks and domains. This adaptability enables enhanced performance in specialized areas and encourages collaboration and community engagement.
While GPT-3 impresses with its immense size and extraordinary capabilities, it has some limitations. Being a proprietary model, GPT-3 restricts accessibility and hampers the extent of modifications that developers can make. On the other hand, open-source LLMs promote inclusivity, enabling a broader range of developers to contribute, understand, and modify the underlying models. This open nature fosters innovation and advancement in the field of natural language processing.
GPT-3’s pre-trained nature allows it to excel in generating coherent and contextually accurate text. Its responses often rival those produced by humans, making it a formidable language model. Open-source LLMs, while not matching GPT-3’s performance out of the box, offer the advantage of customization. Developers can fine-tune these models for specific use cases, tailoring their behavior to meet specific requirements. Additionally, the transparency of open-source LLMs empowers developers to delve into the model’s architecture and parameters, allowing for deeper understanding and modifications.
Differences in Model Architecture and Training
GPT-3 and open-source language models (LLMs) exhibit differences in their model architecture and training methodologies, which contribute to their unique characteristics and performance capabilities. Understanding these distinctions provides insights into how these models operate and excel in different areas of natural language processing.
GPT-3, with its massive 175 billion parameters, utilizes the transformer architecture. This architecture consists of multiple layers of self-attention mechanisms and feed-forward neural networks. The transformer’s self-attention mechanism enables the model to consider the interdependencies between different words in a sentence, capturing the contextual relationships necessary for generating coherent and contextually relevant text. The large number of parameters in GPT-3 allows for a deeper and more complex representation of language, enabling the model to exhibit an impressive grasp of semantics.
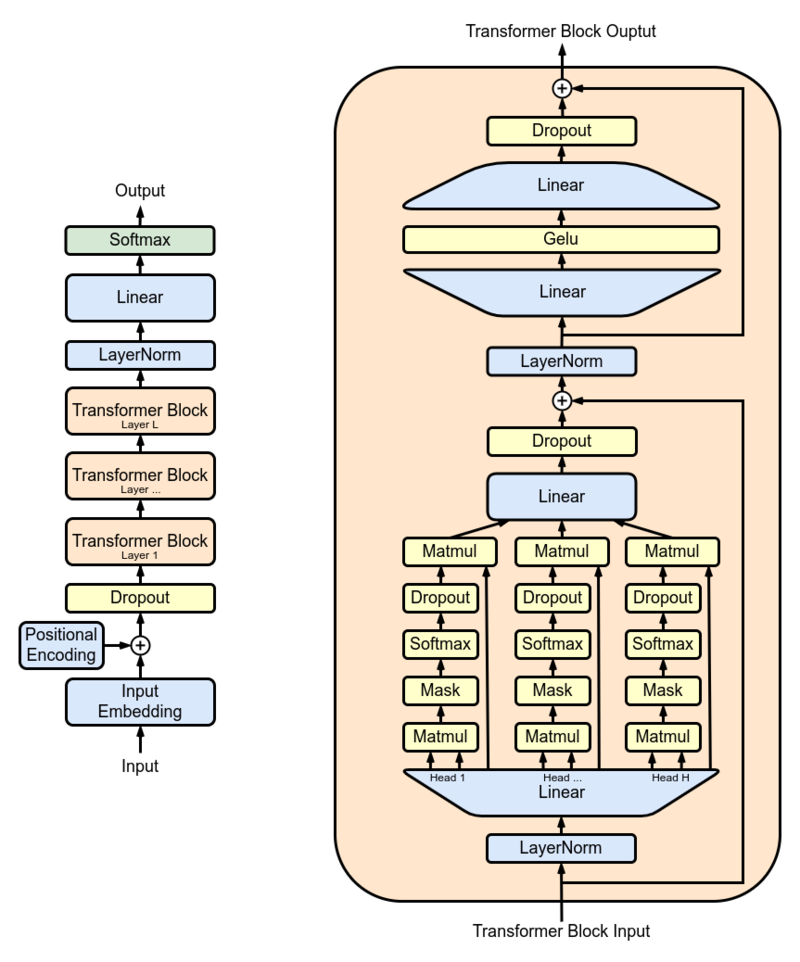
In contrast, open-source LLMs may employ different architectures, such as the GPT-2 architecture, BERT (Bidirectional Encoder Representations from Transformers), Transformer-XL, or XLNet. These architectures vary in terms of their model design, number of layers, attention mechanisms, and other architectural components. Each architecture has its strengths and trade-offs, making it suitable for different tasks and domains.
The training methodologies of GPT-3 and open-source LLMs also differ. GPT-3 is trained in a pre-training and fine-tuning paradigm. During pre-training, the model is exposed to a massive corpus of text data from the internet, learning to predict the next word in a given context. This unsupervised training allows the model to acquire a broad understanding of language patterns and structures. After pre-training, GPT-3 undergoes fine-tuning, where it is trained on specific tasks with labeled data, enabling it to adapt its language generation abilities to more specific applications.
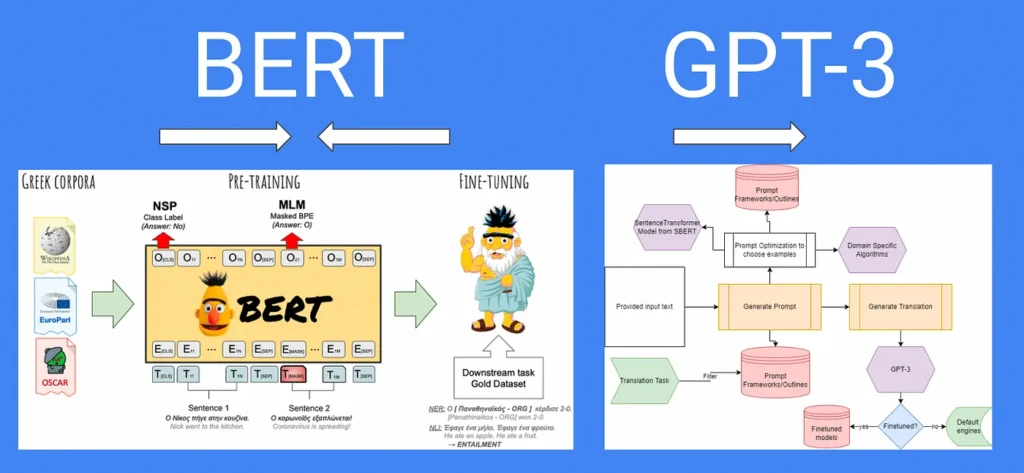
Open-source LLMs also typically follow pre-training and fine-tuning paradigms, although the specific training methodologies may vary. For instance, BERT employs a masked language model objective during pre-training, where certain words are randomly masked, and the model learns to predict them based on the surrounding context. Transformer-XL introduces a recurrence mechanism to capture longer-term dependencies in language, while XLNet utilizes a permutation-based training approach that maximizes the model’s understanding of the dependencies between all possible word permutations.
These differences in model architecture and training methodologies contribute to the unique strengths and performance characteristics of GPT-3 and open-source LLMs. GPT-3’s large size and extensive training data allow it to capture a broad understanding of language and generate highly coherent and contextually accurate responses. Open source LLMs, while generally smaller in scale, offer flexibility in architecture and training, allowing for customization and optimization for specific tasks and domains.
Performance Comparison with Examples
When it comes to performance, GPT-3 stands out with its massive size and extensive training. It has demonstrated remarkable language generation capabilities, often producing responses that are indistinguishable from the human-written text. GPT-3 excels in tasks such as text completion, summarization, and question-answering.
For example,
import openai
import transformers
import torch
openai.api_key = "YOUR OPEN AI API KEY"
# Text completion prompt
prompt = "The sun was shining brightly in the sky, and the birds were singing"
# Generate text completion using GPT-3
gpt3_response = openai.Completion.create(
engine="davinci",
prompt=prompt,
max_tokens=64,
)
# Print GPT-3 response
print("GPT-3 generated text:")
print(gpt3_response.choices[0].text)
tokenizer = transformers.BertTokenizer.from_pretrained('bert-base-uncased')
model = transformers.BertForMaskedLM.from_pretrained('bert-base-uncased', output_hidden_states=True)
text = "The sun was shining brightly in the sky, and the birds were [MASK]"
input_ids = tokenizer.encode(text, add_special_tokens=True, max_length=128, truncation=True)
input_ids = torch.tensor(input_ids).unsqueeze(0)
with torch.no_grad():
outputs = model(input_ids)
logits = outputs[0]
predicted_indexes = torch.argmax(logits[0, -1], dim=0)
predicted_token = tokenizer.convert_ids_to_tokens([predicted_indexes.item()])[0]
generated_text = text.replace('[MASK]', predicted_token)
print("Bert generated text: ",generated_text)Generates an output
GPT-3 generated text:
in the trees; everything on the ground and in the sky seemed to be rested from the enchantment. Frankie hurried away from the field by which she had met the birds. She was very glad to be home again, and yet there was something in her heart that could not be satisfied, I think, because all the people
Bert generated text: The sun was shining brightly in the sky, and the birds were .GPT-3 can generate a complete story that captivates readers. It showcases its ability to understand the context and generate coherent narratives. Similarly, in a question-answering scenario, GPT-3 can provide accurate and detailed answers based on the given input, displaying a deep comprehension of the subject matter.
Open-source LLMs, on the other hand, offer good performance but often require customization and fine-tuning for optimal results. These models, such as GPT-2, BERT, and others, have been successfully applied in various use cases. For instance, BERT has demonstrated excellent performance in natural language understanding tasks, including sentiment analysis, named entity recognition, and text classification. GPT-2 has been utilized for content generation, text summarization, and dialogue systems.
Use Cases and Applications
Both GPT-3 and open-source LLMs find applications across a wide range of domains. GPT-3’s exceptional language generation capabilities make it valuable in content creation, creative writing, and storytelling. It can be used to automate customer support, generate personalized recommendations, and enhance language translation services.
Open-source LLMs provide flexibility and customization options, allowing developers to tailor the models for specific use cases. These models have been widely adopted in sentiment analysis, text classification, chatbots, information retrieval systems, and more. They have empowered developers to build specialized language models that cater to domain-specific needs.
Cost and Accessibility
One notable difference between GPT-3 and open-source LLMs lies in their cost and accessibility. Open-source LLMs are freely available, allowing developers to experiment, modify, and deploy them without incurring significant expenses. This accessibility enables a broader range of developers to leverage these models for various applications.
On the other hand, GPT-3 is a proprietary model, and its usage comes with associated costs. OpenAI has introduced API-based access to GPT-3, which requires developers to pay for the user based on factors like the number of tokens processed and the level of access. The cost of using GPT-3 can be a consideration for individuals and organizations, especially for projects with limited budgets or experimentation needs.
Community and Support
The open-source nature of LLMs fosters community engagement, collaboration, and support. Developers can contribute to the improvement of these models, share knowledge, and collectively enhance the capabilities of open-source LLMs. Community-driven initiatives provide resources, libraries, and frameworks that facilitate the implementation and utilization of these models.
GPT-3, being a proprietary model, limits community contributions and modifications to its underlying architecture and parameters. However, OpenAI has been actively engaging with the developer community and exploring partnerships to promote the responsible use and development of GPT-3. OpenAI’s efforts in soliciting feedback, addressing biases, and addressing ethical concerns contribute to the responsible advancement of language models.
Comparison Table
| Parameters | GPT-3 | Open Source LLMs |
|---|---|---|
| Model Size and Parameters | 175 billion parameters | Varies (e.g., GPT-2, BERT, Transformer-XL, XLNet) |
| Training Data | Large-scale Internet text data | Varied, but typically large-scale text corpora |
| Availability and Accessibility | Proprietary model, limited accessibility | Freely available, accessible source code |
| Performance Out of the Box | Exceptional language generation capabilities without additional fine-tuning | Good, but may require customization and fine-tuning for optimal results |
| Use Cases | A broad spectrum of language-related tasks, including text completion, summarization, creative writing, and question-answering | Wide range of applications, including content generation, text classification, language translation, sentiment analysis |
| Cost | Higher costs associated with licensing and usage | More cost-effective due to free availability |
| Customization | Limited, proprietary nature restricts extensive customization | Flexible, can be fine-tuned for specific tasks and domains |
| Transparency | Limited access to model architecture and parameters | Source code available, allowing for understanding and modifications |
| Scalability | Limited to the specific model size of GPT-3 | Can be scaled to larger models with increased training resources |
| Future Outlook | Proprietary advancements by OpenAI, ongoing efforts in addressing ethical concerns | Continuous community-driven improvements, customization, and innovation |
Conclusion
In conclusion, GPT-3 and open-source LLMs each have their own strengths and applications. GPT-3’s impressive language generation capabilities make it a powerful tool for a wide range of tasks. However, its proprietary nature and associated costs can limit accessibility and customization.
Open-source LLMs provide flexibility, customization options, and cost-effectiveness. They have been successfully applied in various domains, although they may require additional customization and fine-tuning for optimal performance. The future outlook for both GPT-3 and open-source LLMs is promising, with ongoing advancements in language model research and development. The collaboration between proprietary models and open-source initiatives can lead to the evolution of more sophisticated and accessible language models, benefiting developers and users alike. Ultimately, the choice between GPT-3 and open-source LLMs depends on specific needs, resources, and the level of customization desired for a given project or application.