
Introduction
With a plethora of AI research published every week, there have been exciting developments in open-source LLMs with the release of the Orca paper. Falcon models have gained a lot of attention since their release on May 31st, falcon-40b-instruct ranks 1st on the open-source leaderboard and is available completely free to use. We will discuss the Orca model’s paper release in this article, and the SpQR paper which unravels a new technique that enables near loss-less compression of LLMs. It implies we can run 33B parameter LLM on a single 24GB consumer GPU.
Orca will soon be available on open source. Let’s find out how Orca addresses key limitations of top models like Vicuna-13b, and koala-13b. How the 13B- parameter(13 billion) Orca model closes to the performance of ChatGPT-(175B parameters) and GPT 4-(1 trillion parameters).
Imitation Learning
It is a form of supervised learning that aims to train the model by demonstrating the desired behavior. It resembles the idea of Reinforcement learning
1)The models learn to react or behave
2)w.r.t environment and a
3)teacher demonstrates and teaches how to perform so the model can learn.
With Large Foundation Models(LFMs) like ChatGPT and GPT-4 around, the following question arises:
Can we use the model itself to supervise its own behavior or that of other AI models?
The question forms the basis for studies using ChatGPT and GPT-4 as teachers to generate large datasets for instruction tuning, and to train smaller models such as Alpaca, WizardLM, and Vicuna.
What is Instruction tuning?
Instruction tuning is a technique that allows pre-trained language models to learn from input (Linguistic descriptions of the task) and response pairs. For example,
{“instruction”: “Arrange the words in the given sentence to form a grammatically
correct sentence.”, “input”: “the quick brown fox jumped”, “output”: “the brown fox jumped quickly”}
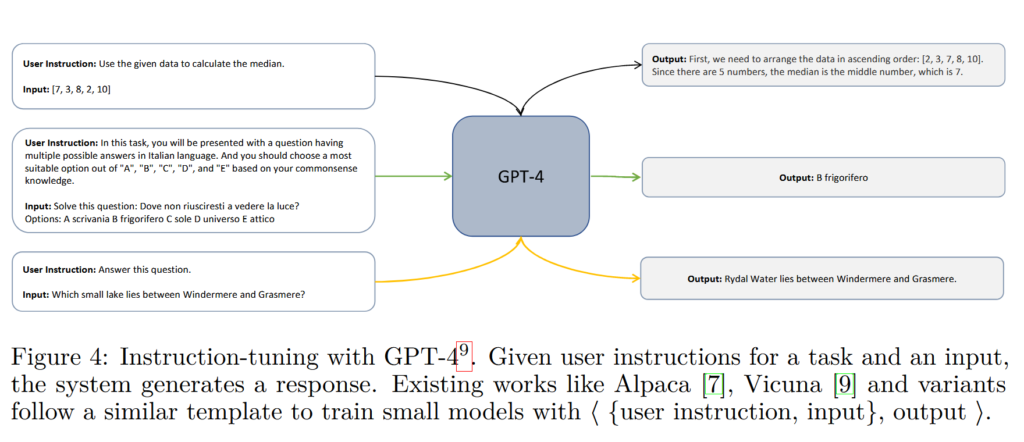
Instruction tuning improves the performance of pre-trained language models by fine-tuning them. Its focus is not on improving LLm to solve a specific task, but to make it capable to solve NLP tasks in general. Training at larger scales makes the model generalize from instructions in the training data to tackle unseen tasks.
Key Challenges in Imitation Learning
Through Imitation learning, Vicuna-13b only retains 48% of ChatGPT quality on complex BigBench-hard benchmarks. The challenge is that existing methods rely on imitation learning from ⟨query, response⟩ pairs. The teacher model(LFMs) generate <query-response> pairs, and then student LLMs are trained on this data. (Have a look at the Instruction Tuning Figure above)
The instruction tuning process discussed earlier lacks details on the reasoning process through which the teacher LFM arrives at the response. This leads the LLM weights to imitate the mere style of the answer when it fails to reason with ⟨query, response⟩ pairs. The model has to mimic teacher LFM only based on its answer. The teacher(LFMs) evaluates the student models, which is an important aspect to consider. In Vicuna-13B’s case, GPT-4 is the teacher model, meaning the evaluation includes GPT-4’s bias as a judge.
The paper “The False Promise of Imitating Proprietary LLMs” provides a detailed analysis of this issue.
Let’s question ourselves:
How to solve this problem? How to make the models imitate the reasoning capabilities of LFMs?
Training Orca 13B and Mastery of Imitation Learning
You are on the correct road if you considered providing the models with detailed responses as training data. Researchers of Orca provided a detailed reasoning and chain of thought process of teacher LFM to student model, to allow the student model to mimic LFM’s “thought” process.
Going beyond Instruction Tuning, we have an improved method called Explanation Tuning.
Explanation Tuning for Better Imitation
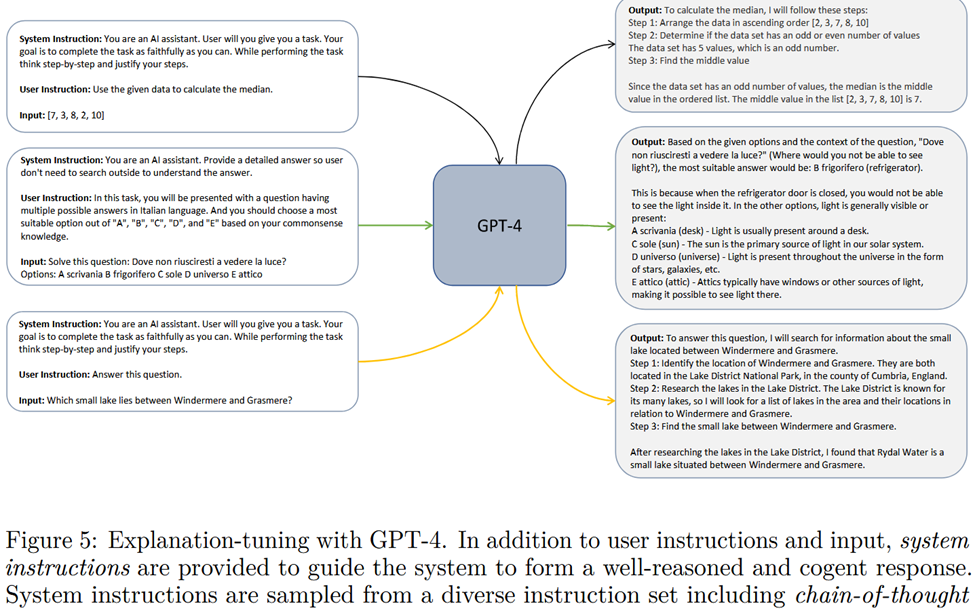
To address these shortcomings discussed, the researchers at Microsoft incorporated large-scale training with diverse tasks, complex instructions, and rich imitation signals to train Orca. Rich imitation signals imply that mere ⟨query, response⟩ pairs are weak imitation signals. As a result of weak imitation signals, the student model fails to imitate the reasoning process of teacher LFM. To carry out Explanation Tuning each instance in training data contains ⟨ System message, User query, LFM response ⟩.
A System message is added to the beginning of the prompt to provide LFM with essential context, guidelines, and details. 16 hand-crafted System messages are used to evoke GPT-4 with detailed responses and include tailored step-by-step reasoning in its response.
User-query is the actual task we want LFM to perform and student LLM to learn from. For training, 5 million user queries were sampled from FLAN-v2 collection(it is a Data collection for effective instruction tuning of LLMs it balances the tasks and prompts that you fine-tune the model upon).
The training goes at 2 levels. First The queries are passed to ChatGPT and 1 million of the 5 million user queries are passed to GPT-4 to collect responses. These 1 million queries are randomly sampled out of the 5 million user queries.
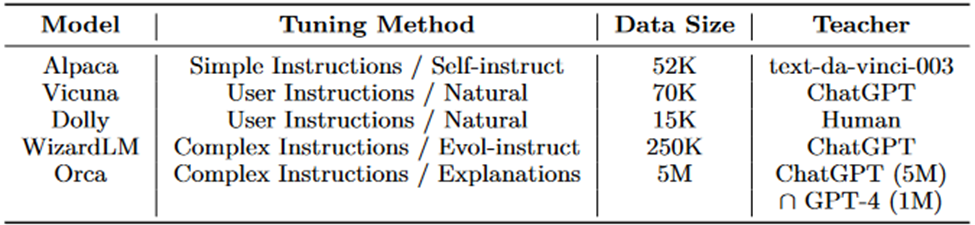
Remember that Vicuna-13B was the best open-source model until the release of the 40B-Falcon model on the open LLM leaderboard. For a deeper understanding of why and how Orca is better than other open-source models look at the following table. The Table depicts tuning methods, training data size, and Teachers of recent open-source LLMs trained through imitation learning.
Look at training instances from Figure 4(Instruction tuning) and Figure 5(Explanation tuning), because Orca trains on 5 million of these curated instances with detailed reasoning, and one can understand why Orca’s imitation quality is top-notch.
Can you improve performance by only using GPT-4 as a teacher?
The Orca research paper explains the reason for not completely leveraging GPT-4 as the teacher as follows:
1) Cost and Time constraints 2) Capacity gap between Orca and GPT-4.
To understand the capacity gap think of ChatGPT acting as an intermediate teacher. It reduces the gap between the capabilities of Orca and GPT-4 initially. Orca is first trained on FLAM-5M with ChatGPT as a teacher model. So then when it learns difficult examples along with reasoning from GPT-4 in 2nd stage, it can capture the reasoning better than training alone on GPT-4. It can be thought of as ChatGPT helps Orca with taking baby steps towards reasoning such that it can keep up with complex reasoning steps of GPT-4. It is like learning to walk before learning to ride a bike. You can see the performance of Orca with and without ChatGPT as an intermediate teacher in the following table
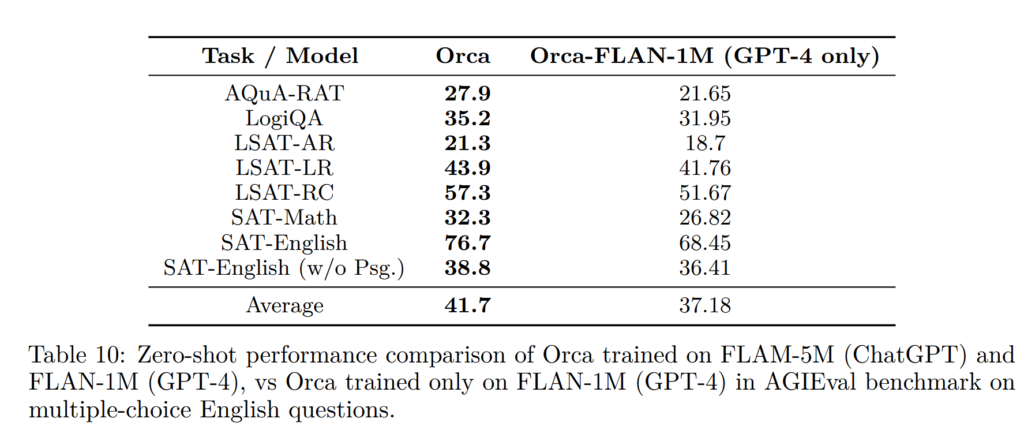
Comparison, and Benchmarks
What are AGIEval and BigBenchHard benchmarks?
AGIEval focuses on evaluating AI models’ abilities in generating creative and diverse responses. Benchmarks like AGIEval, which relies on standardized tests such as GRE, SAT, LSAT, etc., offer more robust evaluation frameworks.
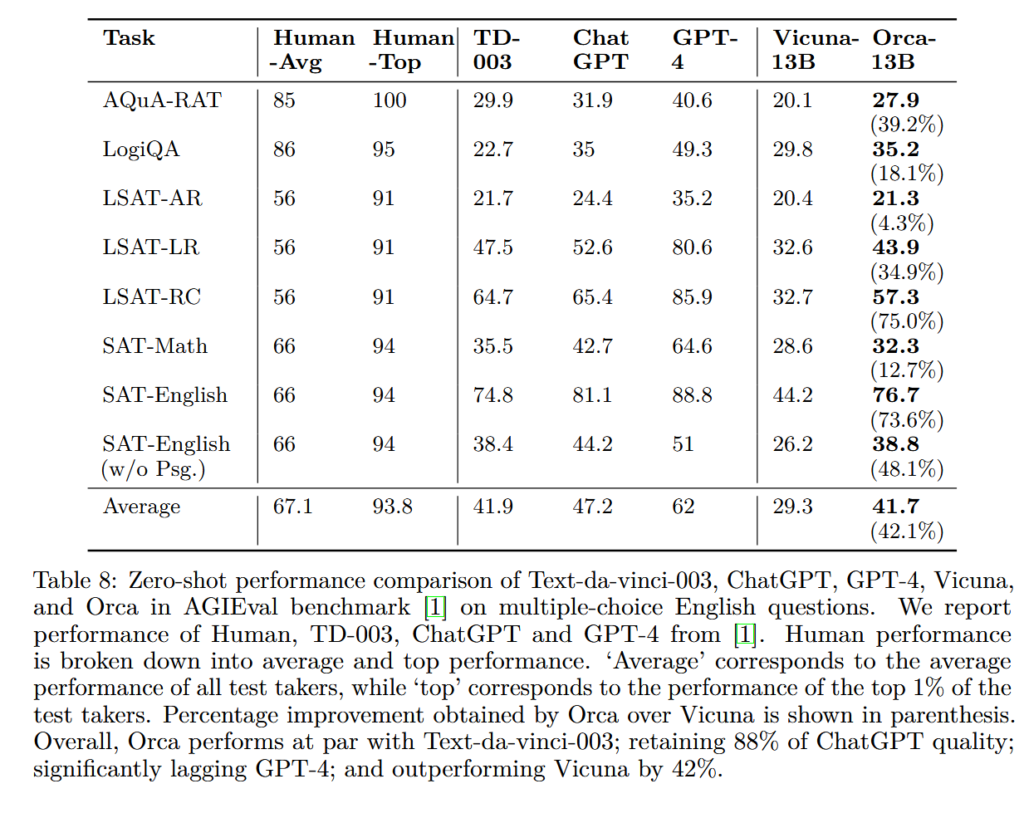
On the other hand, BigBenchHard is a complex benchmark that measures how well a language model can understand and answer tricky questions.
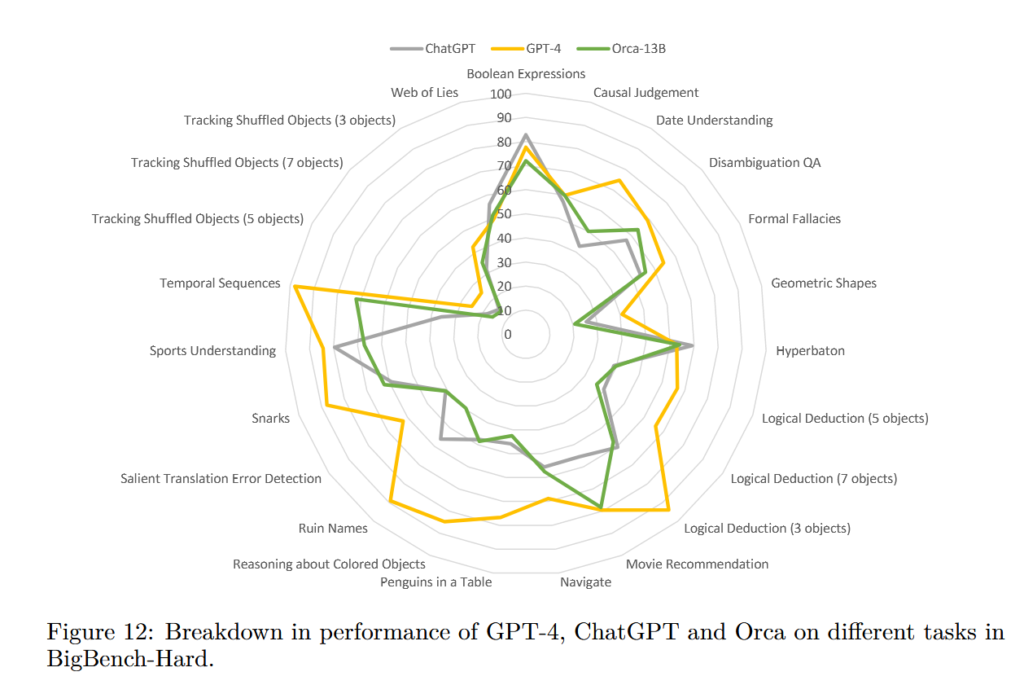
Limitations of Orca
Orca is built upon the LLaMA model family and retains many of its constraints, and the common limitations of other large language models. It matches ChatGPT performance and is still substantially behind GPT-4. Notice that Orca’s performance is greatly influenced by the data used for explanation tuning because it learns to reason from steps in the data. As the Orca model is trained to imitate GPT-4, it can be seen to inherit both the advantages and shortcomings of GPT-4.
Conclusion & Implications
It’s impressive how Orca outperforms the current open-source models by 40% to 100%, it performs at par when compared to Text-da-Vinci, and retains almost 90% of ChatGPT quality. It is exciting research, leveraging what seems close to human-like learning to build a 13 billion parameter model that incorporates all essential knowledge from LFMs.
You can run and work with these powerful student models remotely on your laptop. With only 10% of the size of ChatGPT parameters, Orca provides efficient computation. Orca’s paper states that learning from step-by-step explanations significantly improves models regardless of their size. This might result in reduced API charges to leverage GPT-4 tier performance as time passes.
For more details about Orca, refer to Orca: Progressive Learning from Complex Explanation Traces of GPT-4 paper. In the article, I’ve tried to explain important ideas presented in the paper and the concept of Imitation learning. Below are some exciting and relevant studies which you can refer to intrigue yourselves. Try testing the Falcon model at h2oGPT it’s free and check out its exciting features.
With this in mind, just ponder on how to customize the LLMs & LFMs for a specific task at work. Langchain can be used to build amazing tools around core LLMs with very few lines of code. Here are some captivating reads on Langchain that’ll get you started Mastering Prompt Templates with LangChain & Keeping Large Language Models Up to Date: Introducing Retrieval Augmentation with LangChain
The False Promise of Imitating Proprietary LLMs
Large Language Models as Tool Makers
The Flan Collection: Designing Data and Methods for Effective Instruction Tuning
https://huggingface.co/blog/falcon
SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression